卡内基梅隆大学: AI推理新突破让机器如侦探破案
- 2025-08-02 15:31:31
- 330
这项由卡内基梅隆大学的曲雨潇、杨明煜等研究人员与抱抱脸公司合作完成的研究发表于2025年3月,论文标题为《通过元强化微调优化测试时计算》。有兴趣深入了解的读者可以通过arXiv:2503.07572访问完整论文。
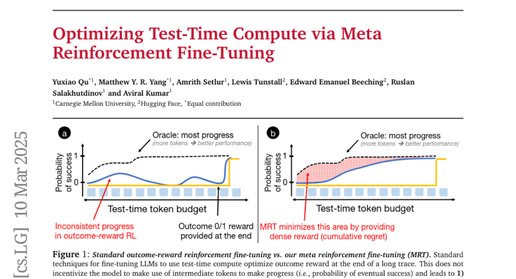
当我们面对一道复杂的数学题时,通常会先尝试一种解法,发现不对后再换另一种思路,有时甚至需要推翻之前的步骤重新开始。这种"边思考边调整"的过程其实就是人类解决问题的智慧所在。然而,目前的人工智能大语言模型在处理复杂推理任务时,就像一个只会按部就班的学生,要么一次性给出答案,要么虽然能"思考"很久但往往做无用功,白白浪费了宝贵的计算资源。
研究团队发现了一个有趣的现象:现有的AI模型在"思考"时间越长,表现并不一定越好。这就像让一个侦探有更多时间调查案件,结果他却在已经走过的死胡同里反复打转,而不是去探索新的线索。更令人惊讶的是,有时候让AI简单粗暴地多试几次不同答案,反而比让它长时间深度思考效果更好。
这个问题的根源在于,目前训练AI的方法就像只看最终破案结果来评判侦探的水平,完全不管侦探在破案过程中是否每一步都在朝正确方向前进。这样训练出来的AI自然不知道如何有效利用思考时间,经常在错误的道路上越走越远。
为了解决这个问题,研究团队提出了一种全新的训练方法,叫做"元强化微调"(MetaReinforcementFine-Tuning,简称MRT)。这种方法的核心思想是教会AI在每一个思考步骤中都要有所进展,就像训练一个侦探不仅要破案成功,还要确保每次调查行动都能获得有价值的信息,朝着真相更近一步。
一、重新定义AI的"思考"过程
在传统的AI训练中,研究人员通常把AI的输出看作一个整体,只关心最终答案是否正确。这就像评价一部电影只看结局好不好,完全不考虑情节发展是否合理。研究团队意识到,要让AI更好地利用思考时间,就必须把这个思考过程拆解成一个个小的"片段"或"情节",然后评估每个片段是否真的有助于解决问题。
研究团队将这些思考片段称为"episode"(情节),就像把一部长电影分成若干个章节。在数学推理任务中,一个情节可能是AI尝试一种特定的解题方法,或者是AI意识到之前的方法有问题并决定回头重新开始。关键是,每个情节都应该让AI离正确答案更近一步,而不是在原地打转或者越走越远。
为了衡量每个情节是否真的有用,研究团队引入了"进展"(progress)的概念。这个进展就像侦探破案时的"信心指数",衡量的是经过这个情节的思考后,AI解决问题的把握有多大。如果一个情节让AI的信心指数上升了,说明这个情节是有价值的;如果信心指数下降了,说明AI可能走错了方向。
更进一步,研究团队从博弈论中借用了"累积遗憾"(cumulativeregret)的概念来衡量AI使用思考时间的效率。这个概念听起来复杂,其实很好理解。假设有一个完美的侦探能够用最少的时间破案,那么我们的AI侦探每多花一分钟而没有获得相应的进展,就产生了一分钟的"遗憾"。累积遗憾就是把所有这些"遗憾时刻"加起来的总和。一个好的AI应该让这个累积遗憾尽可能小,也就是说,每分钟的思考时间都应该物有所值。
二、现有AI模型的"思考"问题在哪里
为了验证他们的理论,研究团队对目前最先进的AI推理模型DeepSeek-R1进行了深入分析。这个模型被认为是当前AI推理能力的代表,能够在回答问题前进行长时间的"内心独白"式思考。
研究团队设计了一个巧妙的实验来测试这个模型的思考效率。他们让模型处理一些数学问题,但不是等模型完全思考完毕,而是在模型思考到不同阶段时强制打断它,要求它根据目前掌握的信息给出最佳猜测。这就像在侦探调查案件的不同时点询问他:"根据你现在掌握的线索,你觉得凶手是谁?"
结果令人意外。研究团队发现,对于那些需要较长思考时间的复杂问题,DeepSeek-R1模型的表现呈现出一种奇怪的模式:随着思考时间的增加,模型的答题准确率并没有稳步提升,有时甚至会下降。这说明模型在后面的思考中不仅没有获得新的有效信息,反而可能被自己之前的错误思路带偏了。
更有趣的是,研究团队发现了一个"简单粗暴"的替代方案居然效果更好:与其让AI深度思考很长时间,不如让它进行多次短时间思考,然后采用多数投票的方式得出最终答案。这就像与其让一个侦探花一整天时间深入调查一条线索,不如让他快速调查多条不同线索,然后综合判断。在计算资源相同的情况下,后一种方法往往能获得更好的结果。
这个发现揭示了当前AI推理训练方法的根本缺陷。现有的训练方式只关注最终结果,就像只根据破案成功与否来评价侦探,而不管侦探在调查过程中是否每一步都在朝正确方向前进。这种训练方式导致AI学会了"蒙对答案",但没有学会"有效思考"。
三、元强化微调:教AI学会有效思考
基于这些发现,研究团队开发了元强化微调(MRT)方法。这个方法的核心理念是,不仅要奖励AI答对题目,还要奖励AI在思考过程中的每一次有效进展。
传统的AI训练就像教学生做题时只看最终答案对错,而MRT方法则像一个好老师,会仔细观察学生的解题过程,对每一个正确的思路转折都给予鼓励。具体来说,当AI在某个思考情节中让自己离正确答案更近了一步时,训练系统就会给它一个"进展奖励"。这个奖励不是基于最终答案是否正确,而是基于这个思考步骤是否真的有助于解决问题。
MRT方法的巧妙之处在于,它不需要人工标注每个思考步骤的好坏。相反,它通过一个"元证明者"(meta-prover)来自动评估进展。这个元证明者就像一个助手,它的任务是根据AI目前的思考内容给出最佳猜测。如果经过某个思考情节后,这个助手的猜测准确度提高了,就说明这个情节是有价值的。
为了实现这个想法,研究团队开发了两种具体的训练变体。第一种是基于STaR(Self-TaughtReasoner)的方法,这种方法让AI生成大量思考过程,然后只保留那些既最终答对了题目、又在思考过程中表现出稳定进展的样本来进行训练。这就像从学生的大量作业中挑选出那些不仅答案正确、解题过程也很清晰的作业作为范本。
第二种是基于强化学习的方法,这种方法在训练过程中实时给AI反馈。每当AI完成一个思考情节时,系统就会立即计算这个情节的进展价值,并相应地调整AI的行为倾向。这就像在AI思考的每一步都有一个老师在旁边点头或摇头,及时引导AI的思路方向。
四、实验验证:MRT方法的实际效果
研究团队在多个数学推理数据集上测试了MRT方法的效果,包括AIME(美国数学邀请考试)、AMC(美国数学竞赛)等高难度数学竞赛题目。实验结果令人振奋。
在使用相同基础模型的情况下,经过MRT训练的AI在答题准确率上比传统方法有显著提升。更重要的是,MRT训练出的AI在使用思考时间方面表现出了质的改变。传统方法训练的AI经常会产生冗长而无效的思考过程,就像一个絮絮叨叨但抓不住重点的人。而MRT训练的AI则表现出了更好的"思考纪律性",它们的思考过程更加简洁高效,每个思考步骤都更有目的性。
研究团队还发现了一个特别有趣的现象:MRT训练的AI不仅在训练时使用的思考时间预算内表现更好,而且当给它们更多思考时间时,它们也能更好地利用这些额外时间。这就像一个学会了有效学习方法的学生,不仅在规定时间内学习效率更高,给他更多时间时也能继续保持高效率,而不是开始做无用功。
具体来说,在一些测试中,MRT方法训练的模型比传统方法训练的模型在准确率上提升了2-3倍。更令人惊喜的是,在计算效率方面,MRT模型达到相同准确率所需的计算量(用token数量衡量)比传统方法少了1.5-5倍。这意味着MRT不仅让AI变得更聪明,还让它变得更节约。
五、深入理解:为什么MRT方法如此有效
MRT方法的成功源于它解决了传统AI训练中的一个根本性矛盾。在传统训练中,AI面临着一个两难选择:是应该快速给出答案(利用已知信息),还是应该花更多时间探索新的解题思路(探索未知可能性)。这个选择在机器学习中被称为"探索与利用的权衡"。
传统的训练方法没有给AI提供足够的指导来做出这个权衡。它们只是简单地告诉AI:"无论你怎么思考,只要最后答对就行。"这就像告诉一个学生:"我不管你用什么方法,只要考试及格就给你奖励。"这样的指导下,学生可能会develop出各种奇怪的学习习惯,包括一些完全无效的方法。
MRT方法则通过引入进展奖励,给AI提供了更细致的指导。它告诉AI:"不仅要答对题目,还要确保你的每一步思考都是有价值的。"这就像一个好老师不仅关注学生的考试成绩,还会关注学生的学习过程,及时纠正学生的错误学习方法。
从数学角度来看,MRT方法实质上是在最小化累积遗憾。这个概念来自于博弈论和在线学习理论,它提供了一个理论框架来评估决策策略的优劣。在AI推理的语境下,累积遗憾衡量的是AI的思考效率与理想状态的差距。通过最小化累积遗憾,MRT确保AI学会了最优的思考策略。
研究团队还发现,MRT方法的另一个重要优势是它的"预算无关性"。传统方法训练出的AI往往对训练时使用的计算预算有很强的依赖性,如果部署时的计算预算与训练时不同,性能就会显著下降。而MRT训练出的AI则表现出了更好的适应性,无论给它多少思考时间,它都能合理分配和利用。
六、拓展应用:从思考到回溯的智能行为
除了基本的思考优化,研究团队还探索了MRT方法在更复杂推理场景中的应用。他们开发了一种"回溯搜索"的参数化方法,让AI学会像人类数学家一样进行问题求解:先尝试一种方法,如果发现错误就回头重新开始,并且能够识别应该回溯到哪一步。
这种回溯能力的训练特别有挑战性,因为大多数预训练的AI模型在训练数据中很少见到这种"认错重来"的模式。研究团队首先通过一个"热身"阶段的监督学习来教会AI基本的回溯行为,然后再使用MRT方法来优化这个过程。
在回溯搜索的实验中,MRT方法训练的AI展现出了令人印象深刻的能力。它们不仅学会了识别自己的错误,还学会了判断应该回溯到解题过程的哪一步。更重要的是,它们的回溯决策是有效的,每次回溯都能带来解题进度的实质性改善。
这种能力对于AI系统在实际应用中的鲁棒性具有重要意义。在现实世界的问题求解中,很少有问题能够一次性完美解决,大部分情况下都需要尝试、修正、再尝试的迭代过程。MRT方法训练出的AI在这种迭代问题求解中表现出了更高的效率和可靠性。
七、理论分析:进展与长度的微妙关系
研究团队还深入分析了一个有趣的问题:AI的思考长度与思考质量之间到底是什么关系?这个问题对于理解AI推理能力的本质具有重要意义。
传统观点认为,更长的思考过程通常意味着更深入的分析,因此应该带来更好的结果。但研究团队的分析发现,现实情况要复杂得多。他们观察到,在传统训练方法下,AI的思考长度在训练过程中会出现剧烈波动,有时会突然变得非常冗长,但这种长度增加往往不伴随准确率的提升。
相比之下,MRT方法训练的AI展现出了更稳定的行为模式。它们的思考长度相对稳定,但更重要的是,每个额外的思考步骤都更有可能带来实质性的进展。这就像比较两个学生的学习习惯:一个学生可能花很长时间学习但效率很低,另一个学生学习时间适中但每分钟都很专注。
研究团队还发现了一个反直觉的现象:简单地对思考长度进行惩罚(比如鼓励AI用更少的词语回答问题)虽然能够提高效率,但往往会损害准确率。这说明问题的关键不在于思考的长度,而在于思考的质量。MRT方法的优势就在于它能够在不牺牲准确率的前提下提高思考效率,甚至在很多情况下还能同时提升两者。
八、扩展性验证:从小模型到大规模应用
为了验证MRT方法的普适性,研究团队在不同规模的模型上进行了广泛测试。从15亿参数的小模型到70亿参数的大模型,MRT方法都表现出了一致的改进效果。这说明MRT方法捕捉到的是AI推理过程中的某种基本规律,而不是特定于某种模型架构的技巧。
在计算效率方面,研究团队进行了详细的分析。他们发现,虽然MRT方法在训练阶段需要额外的计算来评估每个思考步骤的进展,但这种额外投入在部署阶段得到了丰厚回报。经过MRT训练的模型在解决相同问题时需要的计算资源显著减少,从长期来看是非常经济的选择。
研究团队还测试了MRT方法在"线性化评估"中的表现。这是一种特殊的测试方式,允许AI使用滑动窗口的方式处理超长的思考序列,模拟在有限内存条件下处理复杂问题的场景。结果显示,MRT训练的模型在这种约束条件下仍然保持了优异的性能,展现出了良好的实用性。
九、对比分析:MRT与现有方法的深层差异
为了更好地理解MRT方法的独特性,研究团队将其与多种现有的AI推理优化方法进行了系统比较。这些比较方法包括传统的自我教学推理(STaR)、基于长度惩罚的优化方法、以及一些基于外部验证器的方法。
比较结果显示,MRT方法在多个维度上都表现出了独特优势。首先,在准确率方面,MRT始终能够达到或超越其他方法的最佳表现。其次,在计算效率方面,MRT展现出了明显的优势,特别是在处理复杂问题时。最后,在泛化能力方面,MRT训练的模型在面对训练时未见过的问题类型时表现更加稳定。
研究团队特别关注了MRT与基于长度惩罚方法的比较。长度惩罚方法通过对冗长回答进行惩罚来提高效率,这是一种直观但粗糙的方法。实验结果显示,虽然长度惩罚确实能够减少AI的输出长度,但往往会损害准确率。而MRT方法则能够在提高效率的同时保持或提升准确率,显示出了更高的优化精度。
另一个有趣的发现是,MRT方法与一些启发式的训练策略有着惊人的契合。比如,一些研究者发现,采用渐进式增加训练预算的策略(先用短思考时间训练,再逐步增加到长思考时间)往往比一开始就用长时间预算训练效果更好。研究团队分析发现,这种渐进策略实质上也在隐式地优化思考过程的进展性,与MRT的核心思想不谋而合。
结论
说到底,这项研究解决的是一个我们在日常生活中也经常遇到的问题:如何更有效地思考。当我们面对复杂问题时,往往需要在深入钻研和广泛探索之间找到平衡,需要知道何时坚持当前思路、何时另辟蹊径。卡内基梅隆大学研究团队开发的MRT方法,本质上就是教会了AI这种"聪明思考"的能力。
这项研究的意义远不止于提高AI的数学解题能力。它提供了一个全新的框架来理解和优化AI的推理过程,这个框架可能对整个人工智能领域产生深远影响。我们可以期待,未来的AI助手将不再是那种要么给出简单答案、要么滔滔不绝却抓不住重点的系统,而是能够像优秀的人类专家一样,既深入又高效地分析问题。
更令人兴奋的是,这种"元强化学习"的思想可能会启发更多AI能力的优化。比如,我们是否可以用类似的方法来训练AI更好地进行创意写作、科学研究或者商业决策?这些都是值得期待的未来发展方向。归根结底,这项研究不仅让AI变得更聪明,更重要的是让AI学会了如何变得更聪明,这或许是通向真正智能系统的关键一步。
对于普通人来说,这项研究预示着我们很快就能拥有更实用、更高效的AI助手。这些助手不仅能给出正确答案,还能以一种清晰、简洁的方式展示它们的思考过程,让我们更容易理解和信任它们的建议。这将使AI技术真正成为我们日常工作和学习中的得力助手,而不是一个神秘莫测的黑盒子。
有兴趣深入了解这项研究技术细节的读者,可以通过arXiv:2503.07572访问完整的论文文档,其中包含了详细的实验数据和技术实现方案。
Q&A
Q1:MRT方法是什么?它解决了什么问题?A:MRT(元强化微调)是一种新的AI训练方法,它教会AI在思考过程中的每一步都要有所进展,而不是只关注最终答案。它解决了现有AI模型"思考时间越长效果不一定越好"的问题,让AI学会更高效地利用计算资源进行推理。
Q2:MRT训练的AI会不会比传统方法更难训练?A:虽然MRT需要额外计算来评估思考进展,但这种投入是值得的。实验显示MRT训练的模型在准确率上提升2-3倍,计算效率提升1.5-5倍,从长期来看更加经济实用。
Q3:普通人什么时候能用上这种更聪明的AI?A:研究团队已经在多个开源模型上验证了MRT方法的效果,相关代码和模型正在逐步开放。随着技术成熟,我们有望在未来1-2年内在各种AI应用中体验到这种更高效的推理能力。
- 上一篇:女子给自己签字开了小时无痛
- 下一篇:男童蘑菇中毒去世前说爸爸别担心我
